
Software Carpentry Feedback
Published:
Feedback! Feedback! Feedback!
The first Software Carpentry (SWC) workshop run solo by COMBINE was held recently. We were quite pleased with how it went it, and feedback seems to agree.Just how much agreement there is beween our opinion on how it went and the participant feedback could be a matter for debate, if it weren't for the excessive amount of feedback that we gathered.
This SWC workshop was a direct result of Bill Mills recent trip to Australia. He taught a face to face instructor training course, and members of COMBINE from across Australian became instructors of Software Carpentry. It was little bit meta, learning how to be a SWC instructor during a SWC-style workshop, and sure enough, post it notes and the usual pedagogical techniques of short exercises and participant interactions were on show.
One thing that was new to me was a secondary use for the post it notes - requiring feedback on both things that went well during the day, and things that could be improved. After re-reading the Lessons Learned article by Greg Wilson afterwards, there is a similar usage mentioned as "minute cards", with post its collated during breaks to gauge things that have been learnt or found confusing.
We decided to use the same technique that Bill had, asking for both kinds of feedback at the end of each day, which led to some interesting outcomes.
It's raining feedback
At the end of day 1, we had approximately 60 notes, two post it notes per person. We quickly looked at them as a team at the end of the day, and devised a few corrective actions where appropriate.
I decided to look at them in detail that evening. I'd opened the workshop with the Unix shell and so had some clue that the feedback on these post it notes would likely contain some comments on my own teaching style. They did.
There were two main issues that I had:
- I learnt that my habit of using
clearconstantly to clean up my demonstration terminal was counter productive; workshop participants quickly got lost. When I paused, a blank screen behind me did nothing to reinforce points, or let students ponder what I had written in the terminal. - I'd also had the brilliant idea before I taught the class to alter my
PS1environment variable to match the SWC course materials, so my command prompt was simply:$
Of course, the unintended consequence of this was that when I changed directory (as I frequently did during the session) and the participants missed it (or I had cleared my screen by then!), there was little indication I'd done so unless I was conscious of it and threw in a
pwd.echo "----") and think of a useful PS1 with the current directory or similar.I was pleased with the feedback (both the good and improvements) otherwise, and was happy with the outcome from my first official experience teaching a Software Carpentry module.
I wasn't entirely sure what we would actually do with the notes across the eight instructors who shared duties over the 3 days, apart from quick debriefs, however on a whim that evening I transcribed them all, in part because I've been trying to improve my typing to be > 2 fingers and I figured they'd have to be typed in at some point.
It didn't take too long.
Feedback Clouds!
Part way through Day 2, which was on R, I was sitting in the corner acting as a helper and browsed through the now CSV formatted file of comments.
I thought about the feedback, and how I'd found it valuable. It would be good to show the students that we actually read it, and valued it. I didn't want to just display the comments verbatim, or select just the good ones.The quick solution to this was to use a word cloud!
Now I'm sure there are opinions on word clouds, but I'd been wanting to try one on some kind of toy data for a while; a simple word cloud could show the feedback in a de-identified manner, and show that we had valued it. Since I was in RStudio following the lesson along, I searched quickly: 'wordcloud' by Ian Fellows seemed to fit the bill.
The instructors for that day were up to reading in data from a CSV, and as I looked at the R code an idea slowly crept up.
Looking up at the screen, the R code being discussed was incidentally loading a CSV file at the time, and then it hit me: at the end of the day, I could show a word cloud of yesterday's feedback in RStudio and using concepts that had been taught that day.
As a demonstration and way to reinforce a few concepts (e.g. using libraries, when you might want strings to be factors) I think it was a success.
In R:
library(tm)
library(wordcloud)
feedback <- read.table(
file="swc_feedback_day1.csv",
header=TRUE, sep=","
)
feedback$Day <- as.factor(feedback$Day)
feedback$Comment <- as.character(feedback$Comment)
wordcloud(feedback$Comment,colors=brewer.pal(6,"Dark2"),random.order=FALSE)
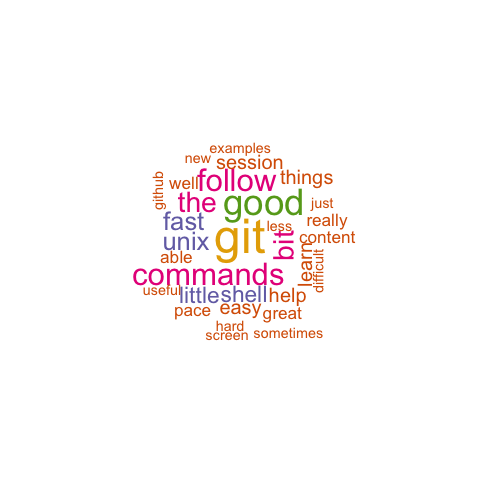
wordcloud package is quite simple to use. A couple of extra lines to remove some stop words (such as "the" featuring prominently above):feedback$Comment <- tolower(x = feedback$Comment)
feedback_cleaned <- removeWords(feedback$Comment,words = stopwords())
wordcloud(feedback_cleaned,colors=brewer.pal(6,"Dark2"),random.order=FALSE)

sub_wordcloud <- function(data,category){
sub_feedback <- data[data$Coded == category,]
sub_feedback_cleaned <- removeWords(sub_feedback$Comment,words = stopwords())
wordcloud(sub_feedback_cleaned,colors=brewer.pal(6,"Dark2"),random.order=TRUE)
}
sub_wordcloud(feedback,"helpers")

I think having helpers around the room is the not so secret weapon of Software Carpentry.
When in rains....
After the fun putting together the R script, I was prepared to show it all again on the last day of the workshop (Python) with more data. Showing the Unix/Git sessions feedback using an R script had been useful for demonstrating the concepts from R however, and using the same script again would do nothing to add to the lesson. But if it was in Python... then it would show the same outcome using the two different languages taught, and reinforce the Python concepts that had been taught that day.
This seemed like such a good idea that I typed in all the post it notes again!
I use Python more than R, and know the Software Carpentry materials better as well, so it was even easier (some library installation issues aside) to get ready for the end of the workshop.
We start by loading the feedback csv file - explaining that I chose Pandas rather than Numpy that students had seen earlier in the day, as Pandas is well suited to mixed data types, whereas Numpy is suited to numerical data.
In Python:
In Python:
import pandas as pd
feedback = pd.read_csv("swc_feedback_day12.csv",delimiter=',')
comments = ' '.join(feedback["Comment"])
Once the feedback is the comments variable, all that is needed is something to make the wordcloud. The virtues of libraries can be reiterated here, and it's relatively easy thanks to this wordcloud library from Andreas Mueller (NB: Install from most recent version in GitHub).
So we can run the code modified from the
wordcloud examples in IPython Notebook/Jupyter, and after a few seconds, we can see that after the first two days of the workshop the students thought that it was:%matplotlib inline
from matplotlib import pyplot as plt
from wordcloud import WordCloud, STOPWORDS
font = "/Library/Fonts/Arial Narrow.ttf"
(w,h) = (800,480)
stopwords = STOPWORDS.copy()
swc_wordcloud= WordCloud(font_path=font,stopwords=stopwords,width=w,height=h).generate(comments)
# Open a plot of the generated image.
swc_wordcloud_image = plt.imshow(swc_wordcloud)
ax = swc_wordcloud_image.axes
ax.axis("off")
plt.show(swc_wordcloud_image)

Good.
Done.
Well that would have been it.. except that after being wowed by R, Python on days 2 and 3, I wanted to ensure that the power of the Unix shell was not lost on the workshop participants!
Too hard you might think, but it's a good opportunity to reinforce the Unix philosophy of small programs that do one thing well.
A word cloud really needs two things: a list of words and values (frequencies/importance), and something to create the cloud image itself.
uniq does all the heavy lifting for the first part, and a blog post from Jwalanta Shrestha (@jwalanta) provides an ingenious awk script for the second. cat swc_feedback_day12.csv |cut -d"," -f "3"|tr " " "\n" |tr '[:upper:]' '[:lower:]'|sed 's/[^a-z ]//g' |awk '{if (length($1)>=4) print $1 }'| sort|uniq -ci|sort -n|./make_cloud > cloud.svg

After the rain
After three days everyone was getting tired, and another light moment to end the day seemed to work.It was a nice way to end the workshop, and some quiet time which gave a chance for the participants to complete both a full feedback form online, and post it notes for that day.
Asking for too much feedback was suggested as a valid response, and though one or two took us up, there was still valuable insight into how the final day had progressed.
Even though it was too late to show directly to the workshop participants, having got this far, data entry for the final day was easy.
Here are all the notes:

and the associated cloud:

In retrospect, as a minimum the data entry of the feedback by day was a good chance to see the progression of the comments, and easier than keeping track of all those post it notes.
The word clouds were almost like a mini-capstone, with a simple purpose executed in multiple languages with knowledge learnt during the workshop.
I think it was a good technique, and would be interested if others also found it so. The code for the above is on GitHub, should other Software Carpentry workshops wish to use and expand on it.
It felt like a fun, but useful bit of code to show at the end of the day, something that was both trivial and interesting.
The only effort is in some data entry, and if it's split amongst instructors, should not be too great a burden.
I think it's worth it.